nand2tetris 読書メモ 1
nand2tetrisの第二版が発売されました。

早速買ったのですが、途中で読むのをやめるのが目に見えるようなので、やめないために読書メモを書いて都度公開しておきます。読書メモ自体は人に見せるために書いてるわけではなく、進捗を可視化するのが主な目的です。
まず何故この本を読もうとしているかというと、自分は特に大学などで訓練を受けたわけでもない独学プログラマであり、普段書いたプログラムがどのようにコンピュータで実行されているか全くわかっていないので、その部分の穴埋めをしておきたかったからです。そのような知識はフロントエンドやBFFなど簡単なバックエンド処理を書いてる分には特に役に立たないと思うのですが、今後のステップアップにつながればいいと思います。
本書では第一部でハードウェア、第二部でソフトウェアを取り扱い、第一部ではHDLというハードウェア記述言語を使用するようです。一体ハードウェア記述言語ってなんなんでしょうか。それぞれのパートは独立して読むことができるようです。第二部の方が仕事でも役に立ちそうですが、コンピュータの処理を隈なく理解することが目的なので第一部から読みます。
第一部ハードウェア
序章
いきなりよくわからんJackとかいう言語を見せられる。擬似言語かと思った。Javaに似てると思ったら実際Java likeらしい。
ハードウェアの部分では機械語に変換した後の謎の処理について扱うらしい。まさに謎の部分だったのでありがたい。各モジュールの名称自体は知っているが、実際何をするかは抽象的にも具体的にも理解していない。
ブール代数。俺は前に論理学を学ぶために入門書を買ったものの本棚の肥やしにしているのである。いつ学ぶつもりだ。


xorゲートの構築。and, or, notを組み合わせてゲートを作成できるが、出力が最終的に同じでも実装は無限にあり、効率が異なる。最終的な出力が正しいか確認するためにモジュールテストを導入する。
TypeScript習得ロードマップ
TypeScriptをおよそ一年と少しほど学んできて、ようやく脱初級者くらいの自覚が芽生えてきました。 この記事では自分がTypeScriptを学んだ際のロードマップを紹介したいと思います。
まずJavaScriptから
TypeScriptはコンパイル時にJavaScriptに変換されます。実行環境で動いているのはJavaScriptなのだから、まずはJavaScriptのことを知る必要があります。
TypeScriptと一緒にJavaScriptを学ぶという方法もありますが、その際に両方を深く学ぶことは難しいでしょう。 そのため、JavaScriptを学んでからTypeScriptを学ぶことがおすすめです。
JavaScriptは複雑な歴史がある言語であり、古い情報リソースを参考にしてしまうと痛い目を見る場合があります。
例えば 変数宣言時にvarを使用しているドキュメントはその時点で信頼性が極めて低いです。初心者の場合はこのような見極めが難しいと思われるため、一つ信頼できるドキュメントを決めてそのドキュメントだけで勉強した方がいいでしょう。
私の場合は文法を学ぶ際はJS Primerを参照していました。
さらに深く学習したい場合はこちらの本が良いと思います。ただし分厚いので読むのに根気がいります。(私は積んでます)
JavaScript 第7版: David Flanagan, 村上 列 + 配送料無料
TypeScriptを学ぶ
JavaScriptの基本的な知識が身についたらTypeScriptを学ぶといいと思います。
私の場合は以下のwebのリソースでちまちまと勉強していました。 TypeScript Handbookが読めれば良いですが、確か日本語翻訳が無かったので少し大変だった記憶があります。
私が勉強し始めた時はTypeScriptについてあまり初心者向けの書籍は無かったのですが、最近出版されたこちらの本はとても分かりやすいです。 基本的にTypeScriptを学び始めた場合は何も考えずにこちらの本を読むといいです。
高度な型の知識などを学びたい場合はこちらの本を読むのがおすすめです。
プログラミングTypeScript ―スケールするJavaScriptアプリケーション開発 | Boris Cherny, 今村 謙士, 原 隆文 |本 | 通販 | Amazon
型レベルプログラミングまで
ここから先は私も試行錯誤しているので誰かに教えてほしいのですが、TypeScriptを深く使いこなす場合は型レベルプログラミングの知識やテクニックを習得する必要があります。 ライブラリの使用者ならばそこまで必要ないと思いますが、ライブラリを作る立場の場合は必須だと思います。
私の場合はこちらのリソースで勉強しています。
勉強方法としては問題にチャレンジした後、解答解説を見て関連ドキュメントを調べています。 ドキュメントを読むだけではどんな時に使用するのかわからない事が多いと思いますが、問題形式で実践してみると結構使いどころが分かると思います。
その他参考にしているレポジトリ
言語を学ぶ際は実際にその言語を使用しているOSSを読んでみるのも良いと思います。 深く理解する必要はないので、ファイル単位で読んでみるといいと思います。
TypeScriptだけでなく、Reactや周辺ツールを学ぶのによく参考にしているリポジトリです。
GitHubのTrendingでTypeScriptでフィルターして上位のレポジトリをボーっと眺めてみたりもしています。
初OSSコントリビュート
タイトルの通り、OSSに初めてコントリビュートしました。
OSSという意味ではfjord bootcampというOSSにも一応コントリビュートしたことがあるのですが、あちらは少し特殊なので除外します。
そこそこの人数に使われているコンポーネントライブラリなので純粋に嬉しいです。npm経由で週に3万ほどDLされているので、結構な人数に自分の書いたコードが配布されることになります。なんだか嬉しさと共に少しの怖さがありますね。
修正した経緯
修正したのはreact-vimeoというvimeo playerを使用するためのコンポーネントライブラリです。私はある用途でこのライブラリを利用していました。開発上の要件で再生速度をあらかじめ保存しておいて、コンポーネントを表示時に保存した再生速度をデフォルトとして再生するという要件があったのですが、既存のライブラリではこの要件を満たす機能はサポートしていないようでした。要件自体はvimeo playerを直接操作して満たすことが出来たものの、せっかくなのでライブラリにデフォルト再生速度を設定できる機能を追加し、PRを出しました。
PRを出した後、反応がないので忘れていたものの、一ヶ月ほど経ってapproveいただき、無事にマージされました。
感想
冒頭にも書いたのですが純粋に嬉しいですね。案外自分でも簡単に貢献できることがわかったので、心理的なハードルが下がりました。
ただしバグを埋め込んでしまうとメンテナの方にも利用者の方にも迷惑をかけることになります。利用者の多いライブラリほど被害が大きくなるので責任を感じますね。
今回は軽微な修正であり、テストコードも書いたので問題はないですが、やはり多少の不安は感じます。この不安は慣れすぎない方が良さそうです。
ところでvimeo社が公開しているplayer.jsというライブラリにもPRを出しているのですが、全然反応がないです…。 大きな会社なのだから、ちゃんと見てくれ😭
テストの無いReactアプリケーションにテストを追加してみたので感想
はじめに
最近チーム内のごたごたでタスクが空いてしまったので常々気になっていた部分の整備を進めていた。
特に気になっていたのはReactで作っているフロントエンドにテストコードが殆ど無いことだった。一応コンポーネントを単体でテストするようなunitテストはあったのだが、フロントエンドをテストするならコンポーネントの単体テストよりも複数コンポーネントを組み合わせて機能をテストするような結合テストの方が有効で必要なので、現状にはあまり満足していなかった。
Write tests. Not too many. Mostly integration.
で、実際に整備してみたわけである。
どうやったか
Jest, react-testing-libraryを使用してコンポーネントをレンダー、シナリオに沿ってuserEventを発火するだけの、簡単なテストを作ってみた。 準備は結構しんどい。まず、対象のコンポーネントがデータフェッチとデータのプレゼンテーションで分離されていないので、コンポーネントがGraphQLリクエストを取得しようとする。 この場合はモックレスポンスを返せるようにしないとエラーになってしまう。 今回はmock service workerを使用してみた。
実際の感想
正直テストについては気休め程度な気がする。もちろん必要だとは思うが、データと状態の変化に伴ってDOMが正しく出力されているかをチェックしていくだけなので、 本当に担保出来ているのか不安にはなる。まあ合ってもいいか程度。サーバと実際に連携して行うE2Eテストの信頼性には全く及ばない。あと、フロントエンドだと結構スタイルが崩れることによる バグが生じるのだけど、その部分はチェックできない。
多分自分のテストのやり方があんまり上手くないんだろうが、現状はそんな感じ。
テストコードでソフトウェアの品質が担保されているかは今のところなんとも言えないが、自分のなかでテストしやすいコンポーネント設計を意識するようになったのは結構大きな成果だった気がする。 データフェッチとデータのプレゼンテーションが混ざってたり、いろいろなロジックがごちゃ混ぜになったコンポーネントをテストするのは正直相当しんどい。 実際にテストを書いてみるとより良いコンポーネント設計について意識を配らせるようになるのは間違いないと思う。
というわけで、リファクタリングとテストの追加を今後も実施します。
NestJSとJWT
Intro
isuconの課題アプリケーションがjwtを使っていたので、興味が湧いた。 なので、試しにjwtを使った認証・認可を実装してみることにした。 ついでなので同じく興味のあったNestJSで実装してみる。
JWTとは?
概要
- Json Web Tokenの略
- サーバは認証後、jwtをクライアントに返し、クライアントは以後認証済みとしてリクエストにjwtを含め、サーバはjwtを検証・認可する。
- JWTはHeader, Payload, Signatureから構成される。
JWTのHeader
{ "alg": "HS256", "typ": "JWT" }
こんな感じでtokenの種類と暗号化アルゴリズムを記録しておくらしい。
JWTのPayload
ユーザの情報などを入れるらしい。生成時間なども入れておくと有効期限を設けて再認証に誘導できるようになる。
JWTのSignature
header, payload, secretを結合した文字列を暗号化して署名としてSignatureに入れる。
JWTのメリット・デメリット
大体この記事を読めば理解できます。
https://fusionauth.io/learn/expert-advice/tokens/pros-and-cons-of-jwts
メリット

jwtを使用した場合はユーザデータを取得する必要なし
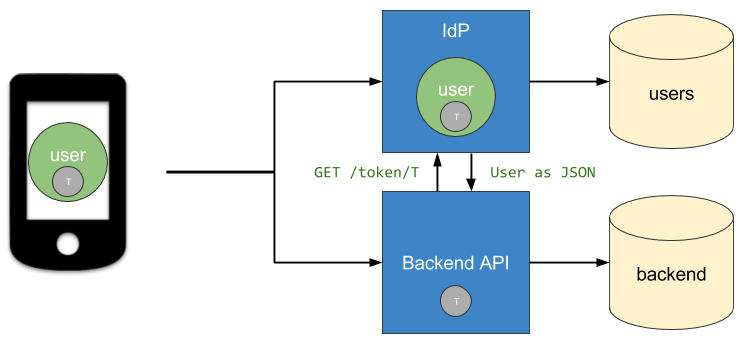
jwtでない通常のトークンではユーザデータを内包していないので取得が必要
引用元 : https://fusionauth.io/learn/expert-advice/tokens/pros-and-cons-of-jwts
マイクロサービスアーキテクチャで採用する分には大きなメリットがありそう。
デメリット
- ログインごとにjwtを新しく発行するため、毎回JSONのserializationと暗号化が必要だが、ユーザが多いとその負荷が無視できなくなる。
- 一回認証したjwtを無効化することが難しい。期限切れを待つ必要がある。
- JWTをXSSなどで盗まれるとユーザ情報も盗まれる可能性がある。
NestJSの認証
次の記事で。
ブレードランナーは良い
映画の中ではブレードランナーが一番好きだったりする。次に好きなのがソナチネで後はぱっと思い浮かんだのがマッドマックスか。
とにかくブレードランナーという映画はマジで素晴らしくて人類の宝なので見たこと無い人は見たほうが良いです。以下ネタバレするのでブレードランナーを見てなかったら読まないほうが良いです。
ブレードランナーを最初に見たのは確か大学3,4年の冬ぐらいだった気がする。当時の私は、大学の勉強は面白くないし、将来どうするかよくわからんしで、かなり参ってて映画ばかり見てた。大学の近くに、よく古い映画とか上映してる映画館があってしょっちゅうそこに行っていた。後は中央図書館が映画貸し出しててそこで見たりしてた。ある時その映画館でブレードランナーの上映企画があって、ブレードランナーとブレードランナー2049を連続で上映するみたいな企画だった。私はブレードランナー2049を見たくて、ついでにブレードランナーも見るか、みたいな気分でブレードランナーを見たのだった。古い映画だし、ネットで難しくてあんまり面白くないみたいな意見も見たからね。初代ブレードランナーについては全然期待してないのだった。
初代ブレードランナーを見て本当に驚いた。人間とは何か、生きるとはどういうことか、という哲学的な視点、雨とネオンの光が降り注ぐ、サイバーパンクな街のあまりの美しさ、暗くてジメジメしていて退廃的な雰囲気。すべてが素晴らしくパーフェクトだった。
何よりも私が気に入ったのは、映画の終盤、ハリソン・フォードが人造人間のボスのルドガーバウアーに追い詰められて、ビルの屋上から落ちそうになったシーンだ。私はもちろん落ちないだろうと思っていた。でも、ここから助かるイメージが全く沸かなかった。ハリソン・フォードは人造人間の連中を皆殺しにしてきて、ルドガーバウアーとしては仇であるわけだ。ここからどうやって助かるのだろうか、と思っていると、ルドガーバウアーがハリソン・フォードを力強く引き上げるわけである。私としてはメチャクチャ困惑した。ハリソン・フォードが困惑したのと同じくらい困惑した。引き上げたルドガーバウアーはゆっくりとハリソン・フォードを見ながら、かの有名なモノローグを呟き、そしてゆっくりと目をつむって人造人間の寿命で死ぬ。

I've seen things you people wouldn't believe. Attack ships on fire off the shoulder of Orion. I watched C-beams glitter in the dark near the Tannhäuser Gate. All those moments will be lost in time, like tears in rain. Time to die.
このモノローグには本当に打ちのめされた。生まれて始めて英文を丸暗記したほどである。とくに最後の詩的表現が良すぎる。All those moments will be lost in time, like tears in rain. 雨の中で絞り出すようにゆっくりと呟かれるその言葉は言葉の力強さを初めて理解したような気分になった。
今思い返すとここでルドガーバウアーがハリソン・フォードを助けたのはいろいろなコンテキストが想定されるわけである。例えば、ルドガーバウアーは直前に人造人間の研究者に合っているから、「実はハリソン・フォードが人造人間で、本人は知らない」ということを知っており、だから仲間のハリソン・フォードを助けた、というコンテキストもあり得るわけである。ただ、私はそうではないと思いたい。ルドガーバウアーは今まで人造人間として生きてきて、強制労働や戦闘に巻き込まれて非人間的な地獄を見てきた。それでも、生きていたいと思うくらい素晴らしい光景を見てきて、自分の生を肯定している、そのことを仇であっても死ぬ直前に人間にわかってもらいたかった。そういうコンテキストのほうが美しいのではないかと考えている。
とにかく、この映画と最後のモノローグには打ちのめされてエンディングが終わったあともしばらく呆然とするほどであった。それくらい素晴らしかった。
あまりにも初代ブレードランナーが良すぎたせいで当初の目的だったブレードランナー2049はCGが現代的なこと以外はとにかくチープにしか感じられず、何の思想も感じられず、面白くない映画にしか感じられないほどだった。単体で見ていれば面白かったかもしれないけど。
もうこの映画が好きになりすぎてサイバーパンク2077とかいうゲームが発売されたときは有給とって遊んだくらいだ。残念ながらそのゲームには期待を裏切られたけど。
そんなわけで、ブレードランナーは私にとってどんな映画よりも好きな映画になったわけである。
")